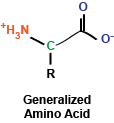
Brief aside: In my chemistry class in undergrad, my TA helped us remember the order of the chemical bonds following polymerization by saying N-H, C-H, C-O, N-H, C-H, C-O, ...
You may remember briefly from any stint in chemistry class that a carbon atom that is covalently bound to four different chemical entities (in this case, a side chain, a hydrogen atom, a carboxyl group, and an amino group) can take two different conformations, depending on how these bonds are spatially oriented. In the case of amino acids, the vast majority of amino acids found in our bodies and used to generate proteins are L stereoisomers. This is a result of the amino acid synthesis machinery structure exclusively generating L amino acids. There are exceptions, but we won't get into that.
As I mentioned, amino acids have a side chain: the part of the amino acid that endows it with its identity. These side chains can be broken into a few groups that we will explore now:

The next set is composed of the aromatic side chains, which includes phenylalanine, tyrosine, and tryptophan. These amino acids all contain an aromatic ring, which makes them relatively nonpolar; thus, they do not interact favorably with water. These amino acids are involved in mediating protein protein interactions and are frequently found at the active sites of enzymes.
Next up: polar, uncharged side chains: asparagine, cysteine, glutamine, serine, and threonine. These amino acids contain hydroxyl, sulfhydryl, or amide groups that mediate interactions with water, but they carry no net charge. An amino acid of note in this family is cysteine, which can react with itself to form cystine, which is important in mediating the formation of disulfide bonds in protein structures.
We'll consider basic side chains next. These amino acids consist of arginine, histidine, and lysine, which all carry a net positive charge in solution. Of note, histidine is commonly found at the active site of enzymes to serve as a protein donor or acceptor.
Finally, we find acidic side chains: aspartate and glutamate. In solution, these amino acids carry a negative charge and are considered acidic.
In the diagram at right, I've drawn up each of the amino acids along with their three-letter and one-letter codes. These codes are frequently used to abbreviate long lists of amino acids.
Another brief aside: Did you know that a single woman designated the amino acid abbreviations? She chose letters that made sense for most amino acids (as you can see above). For tryptophan, for example, she chose W because she envisioned saying tryptophan as twyptophan. Kind of cool, huh?
As a summary, here are the amino acid abbreviations:
- A, ala, alanine
- C, cys, cysteine
- D, asp, aspartate
- E, glu, glutamate
- F, phe, phenylalanine
- G, gly, glycine
- H, his, histidine
- I, ile, isoleucine
- K, lys, lysine
- L, leu, leucine
- M, met, methionine
- N, asn, asparagine
- P, pro, proline
- Q, gln, glutamine
- R, arg, arginine (think aRRRRginine)
- S, ser, serine
- T, thr, threonine
- V, val, valine
- W, trp, tryptophan (tWWWyptophan)
- Y, tyr, tyrosine
So there you have it: 20 amino acids. In addition to these amino acids, our bodies contain several more, including selenocysteine (identical to cysteine but containing selenium rather than sulfur) and ornithine (remember this from glycolysis?). Amino acids can also undergo modifications: for instance, lysine residues can be acetylated. More amino acids and their variants are always being discovered as well.
Now that we have the building blocks of proteins established, the next blog post will focus on how these amino acids can be combined (polymerized) into long structures that make up polypeptides and proteins.
