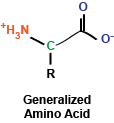In the previous post, we discussed the different levels of protein structure. Here, we will consider more specific details of what makes up protein structure.
 Previously, we talked about how secondary structure consists of alpha helices and beta sheets, but there are even more nuanced forms of secondary structure. For example, different types of alpha helices exist: the 3.613 and 310 helices are different types that consist of 3.6 and 3 amino acids per turn of the helix, they also have different radii and lengths.
Previously, we talked about how secondary structure consists of alpha helices and beta sheets, but there are even more nuanced forms of secondary structure. For example, different types of alpha helices exist: the 3.613 and 310 helices are different types that consist of 3.6 and 3 amino acids per turn of the helix, they also have different radii and lengths.
An interesting little tidbit about alpha helices is that there are certain amino acids that are more likely to be found in helices. These include alanine, glutamine, leucine, and methionine. In contrast, there are some amino acids that do not really fit into a helix: proline, glycine, tyrosine, and serine. These amino acids have structural characteristics (such as proline's "kink") that tend to break helix structure.
Additionally, beta sheets have different properties depending on their orientations. For example, with a parallel beta sheet, the chains of the protein are oriented in the same direction. In contrast, anti-parallel beta sheets have chains that run in opposite directions. See the illustration for a more visual explanation of this trait.
In addition to beta sheets and alpha helices, a few more "secondary structures" exist. I put this in quotation marks because these types of structures are perhaps not classical structures - in that they're not alpha helices or beta sheets. The first is the loop, which is a stretch of amino acids that makes a loop - rather self-explanatory! These loops are important for protein structure because they allow for the creation of relatively compact proteins. In particular, loops can be found in anti-parallel beta sheets, connecting the two beta strands to make the sheet. Sometimes these structures are called hairpins because they are tight stretches of amino acids that hold a protein structure together.
The last secondary structural element we'll consider is the crossover loop, which is similar to the hairpin loop, but it connects portions of a protein at a longer distances. These crossovers can be found especially in anti-parallel beta sheets, connecting the two strands such that they can be anti-parallel.
As mentioned, secondary structure consists of small tracts of protein structure, primarily formed of alpha helices and beta sheets. These secondary structural elements can be organized into specific combinations called motifs. Motifs are commonly-found structural organizations in proteins, such as zinc finger or coiled coil motifs. In the case of a zinc finger motif, there are two beta strands and an alpha helix, making up a fold that looks something like a finger. Within this motif is a zinc ion, hence its name. Several proteins contain this motif, which is primarily involved in DNA- and RNA-binding.
Another level of structure is the domain, which is considered a module of a protein. In general, domains have functions that can be separated from the protein as a whole. Domains are typically large pieces of proteins (think of them as a swing set on a playground - the playground is for kids to play, and the swing set has its own specific function, to swing!). An interesting aspect of domains is that they can be found in multiple proteins with similar functions. For example, some proteins have kinase domains to help with phosphorylation; some have RNA-binding domains; and so on. By detecting domains within a protein, we can infer its function, and this ability has been incredibly useful in predicting the function of new proteins.
Previously, we talked about how secondary structure consists of alpha helices and beta sheets, but there are even more nuanced forms of secondary structure. For example, different types of alpha helices exist: the 3.613 and 310 helices are different types that consist of 3.6 and 3 amino acids per turn of the helix, they also have different radii and lengths. An interesting little tidbit about alpha helices is that there are certain amino acids that are more likely to be found in helices. These include alanine, glutamine, leucine, and methionine. In contrast, there are some amino acids that do not really fit into a helix: proline, glycine, tyrosine, and serine. These amino acids have structural characteristics (such as proline's "kink") that tend to break helix structure.
Additionally, beta sheets have different properties depending on their orientations. For example, with a parallel beta sheet, the chains of the protein are oriented in the same direction. In contrast, anti-parallel beta sheets have chains that run in opposite directions. See the illustration for a more visual explanation of this trait.
In addition to beta sheets and alpha helices, a few more "secondary structures" exist. I put this in quotation marks because these types of structures are perhaps not classical structures - in that they're not alpha helices or beta sheets. The first is the loop, which is a stretch of amino acids that makes a loop - rather self-explanatory! These loops are important for protein structure because they allow for the creation of relatively compact proteins. In particular, loops can be found in anti-parallel beta sheets, connecting the two beta strands to make the sheet. Sometimes these structures are called hairpins because they are tight stretches of amino acids that hold a protein structure together.
The last secondary structural element we'll consider is the crossover loop, which is similar to the hairpin loop, but it connects portions of a protein at a longer distances. These crossovers can be found especially in anti-parallel beta sheets, connecting the two strands such that they can be anti-parallel.
As mentioned, secondary structure consists of small tracts of protein structure, primarily formed of alpha helices and beta sheets. These secondary structural elements can be organized into specific combinations called motifs. Motifs are commonly-found structural organizations in proteins, such as zinc finger or coiled coil motifs. In the case of a zinc finger motif, there are two beta strands and an alpha helix, making up a fold that looks something like a finger. Within this motif is a zinc ion, hence its name. Several proteins contain this motif, which is primarily involved in DNA- and RNA-binding.
Another level of structure is the domain, which is considered a module of a protein. In general, domains have functions that can be separated from the protein as a whole. Domains are typically large pieces of proteins (think of them as a swing set on a playground - the playground is for kids to play, and the swing set has its own specific function, to swing!). An interesting aspect of domains is that they can be found in multiple proteins with similar functions. For example, some proteins have kinase domains to help with phosphorylation; some have RNA-binding domains; and so on. By detecting domains within a protein, we can infer its function, and this ability has been incredibly useful in predicting the function of new proteins.